
Useful steps when thinking about any difficult or disconcerting issue are to state the components of the issue as clearly as possible, and combine them in a way that is logically and mathematically justified.
Such an issue is the recent claim that an 1816 scriptural-style history of the War of 1812 entitled The Late War between the United States and Great Britain (LW) had an influence on the Book of Mormon. Since “influence” can mean many things, the claim in and of itself isn’t necessarily disconcerting to believers in the Book of Mormon. After all, whatever else the translation process involved (divine inspiration, angels, plates, interpreters, stones, hats, scribes), it involved Joseph Smith’s mind. Joseph Smith’s mind and language were immersed in the same culture that produced LW. It would have been very difficult for Joseph Smith, even as translator, to express concepts without reference to his culture. Furthermore, the purpose of scripture is to impart timeless lessons. If some of Joseph Smith’s cultural milieu made its way into the translation of the Nephite record as Joseph recognized obvious lessons from antiquity for himself and his times, I see nothing disconcerting.
The recent claim of influence of LW on the Book of Mormon, however, was deliberately intended to be troubling to believers because the paper presenting the claim was provocatively entitled ‘How the Book of Mormon Destroyed Mormonism.’ Almost immediately after presentation of the paper, posters on several comment boards joined in, describing the claim as the ‘Smoking Gun’ or the ‘Silver Bullet’ that would bring down Mormonism.
Support for the claim was based on a numerical measure of similarity devised by the authors of the paper. Although the measure was an ad hoc index not based on a formal model of English composition, it was based on the sensible idea that shared rare phrases should be more indicative of similarity than shared common phrases. The measure ignored other important things, however, like relative frequencies of matching phrases. When the measure of similarity was calculated between the Book of Mormon and each of 5000 books randomly selected from a large corpus written between 1500 and 1830, LW emerged as most similar to the Book of Mormon after removal of biblical phrases.
LW does have interesting parallels to the Book of Mormon, but Ben McGuire, in an excellent discussion in the Interpreter Foundation’s journal [https://interpreterfoundation.org/the-late-war-against-the-book-of-mormon/], pointed out troubling issues with the similarity measure, problems with the corpus selected for comparison, problems with the process of cleaning the texts and extracting phrases, and interpretational problems based on the simple fact that LW was identified as a result of a massive search. Some critics of the church acknowledged Ben’s thoughtful analysis, but dismissed it, saying that statistical results can always be debated and nothing ever proved via statistics. One critic said that he could plainly see the influence of LW on the Book of Mormon upon a close reading of the texts; he wished he had the skill to devise an appropriate statistical formula to calculate a probability that would express what he thought he saw. This short paper attempts to give this critic as well as believers a formula to do the job.
To formalize things, I start by defining some components:
- Let H be the (hypothetical) proposition that the production of the Book of Mormon was influenced by LW. We immediately notice the need to be specific about what is meant by “influenced.” I suggest that we take “influenced” to mean “was deliberately and physically used by Joseph Smith in his composition of the Book of Mormon.” We do not have to go this far in the critical direction in formulating this proposition, but we do have to be very specific and we have to insist that the definition not change in the course of discussion. So, let’s start with this. Also, let H* be the opposite proposition of H.
- Let E be the observation that, after an extensive search for matching phrases in 5000 randomly chosen books, several hundred non-biblical matches between LW and the Book of Mormon are discovered. Using a weighting system for matching phrases in which weights decrease severely (actually, hyperbolically) as frequencies of occurrence of phrases in the corpus increase, LW turns out to have the highest similarity score of all 5000 books in the corpus.
- A person’s belief in H before encountering E can be expressed as a probability P(H), called the prior probability of H. If someone has no opinion about H, but wants to use probability theory as a mind game for thinking about potential results, it is convenient to set P(H)=0.5. The person’s disbelief in H before encountering E is denoted by P(H*)=1-P(H), which is also 0.5 when P(H)=0.5.
- P(H|E) is the modified (or posterior) probability of proposition H given that E has occurred. Our objective is to evaluate P(H|E) if possible – or at least to discuss it sensibly. P(H|E) must not be confused with the reverse probability P(E|H), the probability of evidence E occurring if H is true. In general, P(E|H) is straightforward to think about while P(H|E) is hard if not impossible to evaluate naively.
The Bayes rule, however, is a relatively straightforward probabilistic formula that indicates, under broad conditions, how to properly calculate P(H|E) from P(E|H) , P(E|H*), and P(H). The Bayes rule summarizes the thinking that has to go on when reasoning from evidence (E) to a proposition (H).
Results using the Bayes rule can be counterintuitive. Here is a classic example. The proposition (H) is that a random 40-year-old woman has breast cancer. The incidence of breast cancer in the U.S. among 40-year-old women is 0.0144. Hence the prior probability P(H) is 0.0144. A mammogram is a good diagnostic test. It has probability P(E|H)=0.84 of being positive when the subject has cancer, and probability P(E|H*)=0.10 of falsely being positive when the subject does not have cancer. A random woman decides to have a mammogram. The test is positive. The patient is terrified, but the critical quantity is P(H|E), the posterior probability that the woman has breast cancer given that the mammogram is positive. It would seem that with such a precise diagnostic test, P(H|E) would be very high. However, it turns out that P(H|E) is only 0.11 = 11%. This example graphically illustrates how bad our intuition can be when reasoning about a proposition given evidence. The value 0.11 was calculated as follows by the Bayes rule:
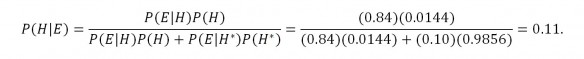
It is easy to get lost in the reasoning of any argument, even an argument that we ourselves are formulating. As a statistician, and therefore being lazy but interested in the truth, I try to offload the work of formulating and evaluating a complex argument, as much as possible, onto the laws of mathematics. The Bayes rule is one of the most versatile and useful of such laws.
To apply the Bayes Rule to the LW – Book of Mormon situation, I propose that we set the priors P(H) and P(H*) to 0.5 to express the idea that we are willing to suspend our innate feelings about the Book of Mormon one way or the other, at least for the sake of argument. Since these proposed values are equal (P(H) = P(H*) = 0.5), the Bayes rule simplifies to
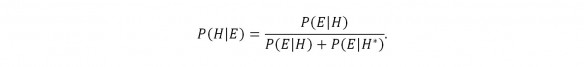
In my opinion, P(E|H) ( = the probability of the evidence assuming that LW is a direct source for the Book of Mormon) is at most 0.8. Even if LW is a source for the Book of Mormon, a book other than LW may well be identified as more similar to the Book of Mormon for several reasons: 1. since the corpus was chosen at random, the weights and therefore similarity results will differ by corpus, 2. the population from which the corpus was selected might tend to not generate optimal weights for choosing the Book of Mormon, 3. the ever-present possibility of unintended parallelisms (especially in the massive search model) between two completely unrelated books might affect identification of LW, 4. a similarity measure that ignores frequencies of use of common phrases or does not adjust properly for lengths of the texts might tend to not identify LW, and 5. books in the corpus may not have been text-cleaned properly leading to over- or under-valuation of the true similarity of LW to the Book of Mormon and other books. Very little information is available on the effects of these 5 issues on P(E|H), so it is premature to assume that P(E|H) is too large.
In my opinion, P(E|H*) ( = the probability of the evidence assuming that LW is not a direct source for the Book of Mormon) is at least 0.5. Some reasons why LW might have a high similarity measure even though it had no influence on the Book of Mormon are: 1. the massive search model might identify unintended parallels in books not connected with the Book of Mormon, 2. unrelated books that use deliberate scriptural language will share many phrases with the Book of Mormon, 3. common phrases might appear for unrelated books that arise in similar cultural settings, 4. common segments such as the copyright statement might induce apparent similarity between two unrelated books, 5. properties of the ad hoc similarity index might accidentally favor certain books in the corpus, and 6. in any corpus there will always be a ‘most similar’ book to the Book of Mormon, even if none of the books in the corpus had anything to do with the Book of Mormon. LW might simply have been that book.
Given these considerations, Bayes rule calculations give:
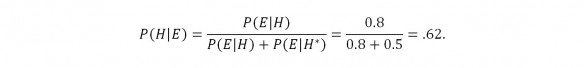
Hence P(H|E) increases at most to around 0.6 from 0.5. That is, the occurrence of E ( = LW has the highest similarity score of all 5000 books in the corpus) increases the likelihood of H ( = a direct influence of LW on the Book of Mormon) from a 50-50 situation to a 60-40 situation. No slam dunk has occurred. You can argue with my reasoning about the values of P(E|H), P(E|H*) and P(H), but now the arguments are focused on real issues that can be debated and investigated carefully.
I recommend the use of the Bayesian framework for discussing the significance of authorship questions using corpus-based similarity statistics. The framework is also useful for determining what future work is needed to clarify the issues and allowing more exact evaluations of the relevant quantities.
http://www.stat.columbia.edu/~gelman/research/published/badbayesmain.pdf
“However, if we are attempting to find a reasonable justification for why we believe as we each do, it would be prudent to base those beliefs on something more than influence and random chance.”
Agreed.
See, we can agree on something! 😉
Dan mentions that 10% doesn’t “move the needle” very far towards the possibility of the LW being directly influential on the BOM. But say that 10% of probability the Late War had an influence on the BOM has a direct influence on someone losing their testimony of the BOM being a unique ancient text…10% of 16 million believers is a large amount….though I’m not sure what the probability of that outcome might actually be.
It does beg the question of why should there be any influence whatsoever, especially since the “witnesses” seem to state a direct, letter by letter, word for word translation.
I suppose that when FAIR takes all of their arguments of evidence in support of the BOM and runs each them through Bayesian calculations, I have little doubt that the probability of evidences actually being such will “move the needle” but little also.
Latterday Skeptic, the question is precisely whether or not there was in influence. The problem with the way you are using the statistics is that you are attempting to make something insignificant significant. For a more closely related issue. linguists can accept about a 5% similarity in the vocabulary of two unrelated languages based on pure change. That is, the word/meaning in one language seems similar to the same word/meaning in another. In spite of apparent similarities, the languages are unrelated.
So the 10% number doesn’t really indicate influence at all. It is actually more likely that it shows that a similar language background was behind the English of the two texts. Think about the implications of your suggestion of influence. Joseph would have had to read The Late War, search it for some random short passages, and then paste in those short passages among the rest of the text while ignoring larger themes and inventing pretty much everything else. Really? Random chance based on similar dialects that similarly imitated the KJV is a much more reasonable explanation that the purported influence.
Mathematics makes my eyes glaze over. I concede that your last statement may be a possibility, but we’re dealing with probability, and mathematics leaves out the human element, and we, as humans, can often be complicated and unpredictible, because we also have desires, feelings, and emotions that drive what we do.
JS had a clear pattern of taking things in his immediate environment/experience, and incorporating them into his theological perspective, some of which shows through in the BOM–e.g. Lehi’s dream vs. his father’s dream, Ammon physically overcome spiritually and raising up prophesying, similar to the camp revival meetings JS was well familiar with, anti-masonry elements, etc…
I don’t hang my hat on the Late War, there are many other places that names and word patterns could come from. As early as “1919, religion theorist Theodore A. Schroeder proposed that some names in
the Book of Mormon were created by Joseph Smith through a process of clang, or
sound association, with other words which were then current and available”
(“Authorship of the Book of Mormon,” in The American Journal of Psychology 30:1
[January 1919], pp. 66-72, in Grunder, 2008). Seems reasonable, to me.
In the same article, Grunder (2008) makes a listing of BOM names and biblical ones and their similarities–what would be the possibility of New World names and Old World ones being associated–also 5%? how about if it relied heavily on Biblical text, and do we find these in the actual New World archeological record as “common”? I believe similarities in names is also a non-starter, but it shows that at least it isn’t something a creative mind can’t come up with.
Looking at JS’s theology as a whole, his whole life in comparison to what we know about ourselves, behaviorally, as humans, and what he did (BOM, start a church, etc…), it is much more explanable (and probable) that he took influences/experiences and creatively/intuitively (perhaps not always consciously) patched many things together from many places, than mathematical calculations alone can attribute. 60/40 is still leaning the expected/normal way. JS can’t always be the exception to the rule..
Latterday Skeptic, at least we now agree that influence is the wrong word. If Joseph is borrowing from his environment, then the phrases just as likely come from the common language and times shared with the author of the Late War. Random chance it is.
Now you add some more coincidences. When do coincidences accumulate into a demonstration of a hypothesis? Frankly, they require a lot more than just the perception of the coincidence, as you have basically admitted about the Late War. The contrary opinion, that the Book of Mormon accurately represents historical information from particular places at specific times is actually much more detailed and much less arbitrary than the examples you suggest. It appears you are unaware of those, or dismissive without dealing with them. Wouldn’t it be prudent to do some research into things that are not pre-selected to accord to your previous assumptions?
Brant, influence is still in play, here. I think the definition, as said in the article, is a reasonable “hypothesis”, in order to clarify what that means, to the author, so that this particular discussion centers on physical use of the text. My concept of what influence means is more broad.
The problem with the BOM language matching some in the Late War simply because the “flowery language” is similar/of the time, is that such “coincidences” work both ways. The claims of apologists that the BOM has chiasmus, hebraism, etc…also become weakened, as the possibility of such can be a co-inkydink that because JS was attempting to imitate the language of the Bible, that’s why it appears as such (rather than being an actual translation of ancient Hebrew-“influenced” text). Same if we extend the same concept to JS’s actual attempt at translation of the facsimiles–of the items that JS seems to have come close to/right, what is the probability that because he had a hypocephalus dealing with the afterlife, that those were obvious coincidental, rather actual translations/(revelations)?
I am a member of the church for over 47 years. I do not, and have not, come to my conclusions based upon predetermined “assumptions”. That’s what a faith based a priori conclusion is. I am not “dismissive” of claimed proofs of authenticity of the BOM being a “translation” of an ancient text. I’d be hesitant to say that I know of all of them, but the one’s I’m generally familiar with are not convincing to me, as they are often extrapolated, massaged, or require the redefining of known words/meaning. In the religious context, I’m much more interested in probabilities, rather than possibilities. I simply wonder if the Bayesian method is applied to, say, NHM being Nahom or any other “hit” that JS got right, according to apologists, what the score might be in those cases. It would be interesting to see, IMO. Of course, how you set up the definitions, in the beginning, would definitely influence the outcome.
Latterday Skeptic:
Changing the focus doesn’t change the problem. “Influence” can come from anywhere, including what Joseph learned in family discussions and Bible readings. What “influence” says is that we learn our language from our environment. That may say something about the phrases we use, or the frequency of certain words, but it doesn’t show connection between our language and other specific texts that probably drank of the same linguistic background.
You mention that coincidence can work both ways, and that is absolutely certain. However, there has been an article specifically looking at the statistical odds of intentionality of chiasmus, so the particular measure you hope gives coincidence actually works in reverse. The indication is that there is intentionality and not random chance. As for Hebraisms, that is controversial and I’m not a proponent.
I’m positive that what impresses one person is completely unimpressive to another. You have been impressed by the Late War argument, and I confess that I can’t see it as a significant argument. I have seen a lot of data that leads me to believe that the Book of Mormon fits into a historical world in specific, non-random ways that correlate to time, location, and surrounding culture. I have no idea if you are aware of that material or not. I suspect that you may be unimpressed with that as well. Agreement will likely not happen. However, if we are attempting to find a reasonable justification for why we believe as we each do, it would be prudent to base those beliefs on something more than influence and random chance.
Having read The Late War recently, and having spent a fair amount of my college and career work in statistics-related fields, I can see that a statistical analysis of the correlation between these two books would not prove anything conclusive. However, I think what most readers will take away from the book is that the flowery, pseudo-scriptural style of writing employed in both The Late War and the Book of Mormon was pretty prominent in the 1800s. And it is totally within the realm of reason to suspect that Smith may have just written the BofM himself.
When apologists claim that there is no way a farm boy with only an eighth-grade education could have written the Book of Mormon, they are neglecting many other factors. First off, Smith wasn’t a “boy” when he published the BofM, but rather an adult man who had spent most of his life since childhood studying from or receiving parental instruction from the King James bible. Also, he had the assistance of an educated man, like Oliver Cowdery, in bringing forth the Book of Mormon.
Could they have contrived the entire book in a short period of time? Absolutely. Did they? That is up to the reader to decide.
I was thinking about how follow-up textual criticism might enter into the Bayesian analysis of LW’s influence. I’d appreciate any corrections or criticisms.
Starting with Dr. Schaalji’s “mind game” outcome of P(H|E) = 0.62, I propose considering what happens if we textual critical analysis of matching 4-grams show common contextual elements, clustering of matched phrases, or synonyms in the corresponding sentences where matches, etc. (I have no background in this, so I presume there are other or better “features” that follow “valid models of English composition.”)
Let the observation of a statistically significant frequency of such shared literary features accompanying 4-gram matches be T.
Let S be the (hypothetical) proposition that the production of the Book of Mormon was “strongly” influenced by LW. By this I simply mean tan updated prior probability of influence, P(S) = P(H|E) = 0.62 from Dr. Schaalji’s working illustration.
Then
P(S|T) = P(T|S)P(S) / [ P(T|S)P(S) + P(T|S*)P(S*)]
= [P(T|S) x 0.62 ] / [P(T|S) x 0.62 + P(T|S*) 0.38 ]
What can we fairly assign P(T|S)?
I would think it would be quite high. Let’s say 0.8 as a conservative estimate.
What can we assign for P(T|S*)?
I would think it would be quite low. Let’s say 0.2 as a conservative estimate.
Then
P(S|T) = [ 0.8 x 0.62 ] / [0.8 x 0.62 + 0.2 x 0.38 ] = 0.87 or 87%
If we take P(T|S) = 0.9 and P(T|S*) = 0.1
P(S|T) = [ 0.9 x 0.62 ] / [0.9 x 0.62 + 0.1 x 0.38 ] = 0.94 or 94%
This seems like a significant shift toward certainty of influence.
A question as I make my way through
Dr. Schaalji writes:
“When the measure of similarity was calculated between the Book of Mormon and each of 5000 books randomly selected from a large corpus written between 1500 and 1830, LW emerged as most similar to the Book of Mormon after removal of biblical phrases.”
My understanding was that a random sample of 5000 books was used to create a baseline from which 130,000 books were tested for similarity. In other words, LW emerged as the most similar of 130,000 books. Am I missing something?
Dr. Schaalji,
This was very interesting. Thank you for this idea.
As I continue to struggle to understand much of this – especially the reasons you propose for why a book other than LW might be identified as more similar to the Book of Mormon and why LW might have a high similarity measure despite having no influence on it – I’d like to challenge two of your ideas and add a question. I am open to the possibility that this may at best reveal my misunderstanding, so I am open to criticism and correction.
1. Definition of “influence.”
You propose that people engaging this type of evidence settle on a definition of “influence” requiring that LW “was deliberately and physically used by Joseph Smith in his composition of the Book of Mormon.”
I understand the importance of consistently applying clearly specified terms, but I suspect this definition introduces a formal bias into the subsequent Bayesian calculus and may not even be relevant to the issue. Let me try explain.
First, I am not sure that it’s necessary for Joseph to be self-conscious of the sources of the phrases he used to express any concept that arose (or were implanted) in his mind. Cognitive science provides evidence that the “natural” generation of thoughts and their transformation into words involve unconscious processes that draw on deep reserves of implicit memories and associations whose origins may be forgotten, conflated, or confabulated. For the same reason I find the requirement of “physical [use]” too restrictive, especially if that is meant to imply Joseph referred to LW at the time of dictation by direct reading.
Second, these two elements combine to imply that fraudulent intent is a requirement of “influence.” Other than this not being a necessary precondition – most of us have no problem identifying deluded false prophets of other faiths – it is irrelevant since establishing intent is beyond the realm of what statistical evidence can establish. An analogy would be the use of statistics to establish the efficacy and safety of a new drug. The confidence in concluding efficacy does not require any demonstration of intent of its producer. Even more importantly, neither does it not require that causal mechanism for the drug’s “influence” on the body be established.
While I am not ready to propose a counter-definition of “influence”, I am thinking it should have an empirical basis and expressed in advance along the lines of a p-value. However, as I mentioned above, I will propose that your definition introduces a bias into the Bayesian calculus after the prior probability P(H) is chosen. Simply put, these two restrictions would have the effect of making – or tending to make – H independent of E insuring from the outset that P(H|E) remains close to P(H).
2. Role of a “loose” translation presupposition
In your discussion you see to presuppose that Joseph employed a “loose translation” of Book of Mormon from characters inscribed on ancient metal plates. But what if Joseph used a “tight” translation, as suggested by Royal Skousen’s text-critical analysis of the earliest Book of Mormon manuscripts and by friendly contemporary witnesses to his dictation method? I think this also serves to make H independent of E.
I bring this up because I am not aware of any positive evidence for a loose translation. Rather, it strikes me as an ad hoc hypothesis designed to “save the appearances” of an ancient record, mostly due to the New Testament n-gram matches that appear in the Book of Mormon. I am open to correction in this assessment of the “loose” translation argument – as with everything else here. However, I can’t see the justification of presupposing a “loose” translation when there are good reasons for discounting it, and not simply because it shields H from E in a pro-prophet sense.
3. Accounting for other apparent influences
With respect to the appearance of New Testament n-grams in the Book of Mormon, how might these fit into an overall Bayesian framework of deciding anachronistic influences? This can be extended to the matches between the BM and the Pearl of Great Price and between the BM and Second Isaiah. There is certainly a prior probability for each of these possible anachronistic “influences.” How would each of their individual P(H|E)’s combine to produce a “meta” conditional probability of influence?
In conclusion, I don’t think it is possible prove that the Book of Mormon isn’t true, particularly with statistics, and even more particularly when belief in its truth is based on “spiritual” evidence. As a faithful LDS Book of Mormon scholar recently said on a podcast, ““Once you allow for the possibility of gold plates and angels … there are all sorts of possibilities to accommodate the evidence that’s there.” Indeed, one might wonder faith should even be associated with probabilistic mode of reasoning.
Thanks in advance for your consideration and criticism.
There is another (but still equivalent) form of Bayes rule that might make this point more clearly and less controversially than the form in the blog above:
odds(H|E)/odds(H) = prob(E|H)/prob(E|H*)
We don’t need to guess individual values for any of the quantities here to show how Bayes’ rule can help us in thinking about The Late War and Book of Mormon authorship and influence questions.
This equation says that the ratio of (posterior odds of H to prior odds of H) is equal to the ratio of the [probability of a true positive (sensitivity) to the probability of a false positive (specificity)]. If a true positive is much more likely than a false positive, the posterior odds increases relative to the prior odds. If a true positive is about as likely as a false positive, the posterior odds stays about the same as the prior odds.
This is important in the Late War situation because there is not much information about how sensitive and specific the Johnsons’ procedures are. In my opinion, sensitivity is decreased and specificity is increased by at least two features of the Johnsons’ study:
1. the massive search model tends to produce false positives.
2. the dependence of weights on a randomly selected corpus (from books of many genres between 1500 and 1830) tends to affect sensitivity and specificity in unpredictable ways; I can conceive of ways in which sensitivity is decreased and specificity is increased.
We don’t have much to go on at this point when evaluating the meaning of the Johnson’s work. If Bayes’ rule can focus our attention on aspects of the procedure that need to be assessed and improved, we are the better for it.
Dan,
It’s the same old problem – my name is just too common. And yes, please do triple my consulting fees.
Bruce:
I just read a response to your essay by one critic who explains it by saying that “the apologists,” in a panic, have “move[d] into full damage control mode by . . . contracting an outside specialist.”
I hope you’re satisfied with your contract! (Is the compensation, which we set at $0.00 per week, adequate? We can triple it, if you like.) And, please, do thank that other BYU statistics professor (also, curiously, named Bruce Schaalje) — the one who, like you, sits on Interpreter’s board and who, like you, contributed to the old “FARMS Review” — for suggesting you to us as an “outside specialist.”
From a non-mathematician’s viewpoint, it would be interesting to do a survey of 1830 literature to determine how many Book of Mormon terms, phrases and concepts are unique and non-derivative. For example, how many other books available to Joseph Smith referred to the ancient city of Nahom? How many described Christ’s — not Israelites’ or Ten Tribes’ — visitation to the New World? What about unknowable concepts such as the existence of a verdant region in Yemen that could be Bountiful? Joseph certainly could have used common phraseology of his day to express ideas, but as Nibley so eloquently points out, he had to be incredibly lucky to include something like Nahom. Did he borrow that from some obscure source? Maybe we should focus the new data searches on corroborating dissimilarities and non-derivative elements.
Perhaps a book on the American Civil War written shortly after the event would have a similar word and phrase correlation to the Book of Mormon and it could then be shown that this also had an influence on Joseph Smith’s writings? 😉
Sounds like an excellent “control” technique in order to test our assumptions and results.
The study was based on shared rare phrases. Another approach would be to study unshared rare phrases and demonstrate the dissimilarity of the books. I wonder how many times the phrase ”and it came to pass” is found in LW? How about the phrases, “for behold;” “spake unto;” “even in a dream;” “said unto him;” “blessed art thou;” “hast done;” “hast been faithful;” “unto this people;” “I commanded thee,” and, “take away thy life?” And these rare phrases are only in one random verse of The Book of Mormon. The Book of Mormon is so unique that the claim that its creation was influenced by any other book, except the Bible, is a desperate absurdity.
This seems like a complementary approach that should work. You would still have to come up with appropriate weights. It would seem that unshared common phrases would be more indicative of dissimilarity than unshared rare phrases.
Theodore, you can explore this question yourself fortunately because LW is available online here or just google it. When I search the document for “it came to pass” I see about 50-60 matches. I’ll let you check out the other phrases you suggest. From reading the first 10 chapters my non-scientific opinion is that the two books have an extremely similar style.
As about one third of the Book of Mormon is about war it appears obvious that there would be a statistical word and phrase correlation with another book on war written in the same English language period.
I’ve made a detailed study of B of M warfare. First, I went through the details of how they were organized. Second, I went through the major wars, campaigns and battles. I concluded the following:
(1) It was Iron Age warfare.
(2) Nephite warfare was heavily influenced by the Old Testament.
(3) Lamanite warfare appears to have been heavily Mesoamerican.
There were no weapons, tactics, logistics, military units or terminology remotely resembling the gunpowder warfare of Joseph Smith’s day. This is assuming he even knew anything about war in 1828.
Interesting. Your theory that Lamanite warfare was Mesoamerican, but different from Nephite warfare, coincides with my thesis that the Lamanite land of Nephi was Mesoamerica and Mexico, and the Nephite lands were north and east of there.
There isn’t space for a detailed discussion, but I wargamed Sorenson’s maps, and they worked perfectly. I used Old Testament warfare as a template, and Nephite warfare is an extremely close fit in terms of command structure, fortifications, unit organization, and so forth. Evidence in the text is fragmentary, but I made sense out of it using the OT.
Lamanite armies appear to have been coalitions, which sounds very Mesoamerican. This explains the brittleness of Lamanite armies compared to the Nephites.
Copymensch:
I would love to read more about your work on this.
Dear Prof. Peterson: It would be an honor, Contact me at this e-mail address, Interpreter will be able to provide it for you.
I would also be very interested in reading more about your work on this.
The conclusion that there is an 11% probability that the woman with a positive test result actually has cancer may seem very strange. An easy way to understand it is to consider what would happen if we randomly selected 10,000 40-year old women and tested them. Since the odds of actually having breast cancer in this example are given as 0.0144, then there should be 144 people on average in a group of 10,000 with cancer, and 84% of them will be detected by the test, giving 121 true positives. But there will be a much larger group with false positives since false positives occur 10% of the time. Among the 10,000 – 144 = 9,856 women without cancer, about 986 can be expected to give false positives. So the total number of women testing positive for cancer will be 986 + 121 = 1107. The women who actually have cancer, the 121 in a pool of 1107 positive test results, represent 121/1107 * 100% = 10.9%. So getting a positive cancer results only gives you about an 11% chance of having cancer. It’s the large pool of false positives that make the odds so low for actually having cancer when the test is positive.
Jeff,
That’s a great explanation. Thanks.
I have no problems with your math, but your assumption that P(E|H*) is at least 0.5 is speculative. In your breast cancer example, P(E|H*), that is, specificity, is calculated from data from large population studies. Your Book of Mormon calculations fail because the P(E|H*) is assigned arbitrarily through rhetorical argument. Even if your arguments are sound, this is a nonmathematical method.
Gary,
You are correct. I admit that my value for P(E|H*) was based on a rhetorical argument rather than data, and I was sure (~0.95) that someone would bring this up. You win the prize.
I listed reasons why I think the probability of a false positive is so high (~0.5). It would be better to have data on this. If we could identify books that for sure were not influenced by any other books in a corpus, we could empirically estimate P(E|H*). But for the time being, the Bayesian approach at least allows us to intelligently discuss our various reasons for choosing a value for P(E|H*), and to sensibly combine the guesses we make for the various quantities. Rather than a failure, I think this approach has great value in thinking clearly about the problem. It’s not the final word.
What value for P(E|H*) would you choose? Do you think my reasons for setting P(E|H*) at 0.5 are mistaken?
I like your approach Bruce. Bayesian analysis is really a really great tool. I have a couple of questions:
1. If P(E|H*) = .5, doesn’t that mean that we should see nearly 50% of the selected sample of books to be classified as matches to the Book of Mormon on a similar level as The Late War?
2. Have you examined the probability that the Book of Mormon is a product of 19th century New England using a Bayesian framework? The probability you estimate of 0.6 for the Book of Mormon being influenced by The Late War given a positive match in the Johnsons’ analysis could then be used with the probabilities of other evidences to update the Bayesian probability.
1. That’s close. P(E|H*) = .5 means that there is a 50/50 chance that some book in the corpus would be as similar to the Book of Mormon by the Johnson’s measure as LW is in the current analysis, even if the Book of Mormon was not influenced by that book.
2. I would have to think about how to actually carry that out, but I like the idea in general. What evidences (data) would you collect?
The analysis done by the Johnsons only shows that “The Late War” and the BoM have a lot of phrases in common, right? It doesn’t have the same story or doctrinal teachings.
What would happen if the analysis that found the late war to have these similarities was done on books published in the near term after 1830? If they could find books published after 1830 that also have a high correlation in phrases, that might cast doubt on The Late War…
Ty,
I agree. That would be a good thing to do.
1. Okay, so if P(E|H*) is the probability that a random book in the corpus scores as high as LW according to Johnson’s metric, we could calculate the likelihood of the observed results occurring if P(E|H*) = .5 is true. He used 100,000 books and no book scored as high as LW, so the likelihood of this would be .5^100,000. This is extremely unlikely.
From eyeballing his graph, if we took something like History of the American Revolution (Warren) as the cutoff with a score of 84, then P(E|H*) = .5 produces a much more reasonable result. Again from eyeballing, it looks like something like 51% of the books were above HAR so P(51000 books scoring less than 84) = (total # ways to match at least 51000 books)/ (total number of ways to match/unmatch all books). The numerator would be the Summation of k = 0 to 51,000 of (100,000!/(k!*(100,000-k)!) and the denominator would be 2^100,000. Luckily the binomial distribution will give the answer when we say n = 100,000 and k = 51,000 and as you can see the probability of this happening by statistical chance are functionally zero.
Based on the numbers Johnson put out, there is extremely strong evidence that P(E|H*) != .5.
2. Data I would suggest would be things like, what is the likelihood that a 20 year old 19th century New Englander could write a historical narrative?
For me, it isn’t the percentage probability that grabs my attention. What peaks my interest is the way the church has always boasted that “The Book of Mormon was translated by the gift and power of God by an unlearned boy. How else could he have done it?…” The “how else-es” were out there and this is what peaks my interest. In my opinion, it just can no longer be said, there is no other way he could have done it. The evidences are growing that various outside texts could well have heavily influenced Josephs “mind”. No doubt Joseph would use his own mind but heretofore the church has always acted as if Joseph could have had little if anything, mentally, to contribute, since he was so “unlearned”. We do know that Joseph could read AND we know he “could have” read some of these “smoking gun” sources. Joseph had a very precocious nature and a very curious mind and he was a researcher through his life. These are the ways he “could have” done it himself. My thesis here may not be very technical as others but certainly it is feasible.
Samuel,
I have always been under the impression that Joseph Smith’s mind was heavily involved, as in:
“But behold, I say unto you that you must study it out in your mind” (D&C 9:8)
Don’t you mean “piqued” your interest?
I’m pretty sure he meant “peaks.” lol
I don’t honestly see how this changes the argument that “Joseph Smith couldn’t have done it.” Barring actual demonstration that he borrowed language and plot ideas from “The Late War” or something of that sort, the case still seems to me quite strong that (a) he couldn’t have written the Book of Mormon and (b) he didn’t write the Book of Mormon.
My point may not PROVE that Joseph “could have”, or did use, outside texts. That is as difficult to prove as it is to prove that he did not use them. The case is no stronger that Joseph did it alone, with no help. There are no plates to view nor actual evidence of any actual “Reformed Egyptian” language. My point would be that the “could haves”, as aid to Joseph, appear to be increasing with time. In my humble opinion, there is more evidence against the Book of Mormon being what Joseph Smith and the LDS church claims it to be. I believe time will reveal that Joseph did have contemporary help of various types and that the book is ultimately not of ancient origin.
“The case is no stronger that Joseph did it alone”
With respect, I fully disagree. There are at least 11 witnesses to the Gold Plates, which is far more evidence than much of history that you and I would say is factual.
Also, the “could haves” have not been increasing – they are invariably refuted time and time again, many times as bold-faced lies or malice-twisted facts. It’s sad that many people don’t read the refutations (like this piece).
But a number of credible witnesses did see (and, in some cases, “heft”) the plates, and “reformed Egyptian” is quite unremarkable (e.g., hieratic and Demotic and even, to some extent, Coptic can be viewed as “reformed Egyptian” scripts).
We obviously weigh the evidence differently in other respects, as well. I personally think that the evidentiary situation of the Book of Mormon is considerably better now than it was 75 or a hundred years ago.
The fact that there are no plates available to look at, no physical evidence, points to the Book of Mormon not being of ancient orgin. Unlike the Bible which has many manuscripts from ancient times including much of the old testament dated to from before the time of Christ in the Dead Sea Scrolls.
While it is true that there is a long documentary history for the Bible, it is not true that we have documents contemporaneous with most of the events of the Old Testament. Until the discovery of the Dead Sea Scrolls, the documents supporting the Old Testament were actually newer than those for the New Testament.
Historians often have to deal with texts that exist in copies that are later than the events described, so not currently having the plates is not a reason to reject the Book of Mormon according to normal historical work. Please remember, however, that there were witnesses who saw them, so even your comparison isn’t to something that never existed, but simply isn’t currently available. Witnesses saw and handled them. If the existence of the plates is the only criterion you use, those witnesses provide that testament to authenticity.
Such simple distinctions cannot be used to make judgements about whether or not the Book of Mormon represents an ancient text. That requires comparisons between that text and history. Those comparisons place the Book of Mormon in a much better light today with our greater knowledge than it did when the book was first printed. It is interesting that the passage of time is increasing the viability of the Book of Mormon as a historical text when one would assume that it would be the opposite, had it been a fantasy.
As Curt Burnett points out below (Nov 7), this imagined feasibility depends entirely upon comparison with substantive matters in the text of the Book of Mormon which could not have been known by Joseph. Since there are many such proven facts, it would not have been feasible for Joseph to have composed the Book of Mormon via “research” at his local library, or even at Harvard College (where he presumably obtained his surreptitious PhD).
Quite aside from the sort of language used in translating the book, it would have been beyond the capability of any scholar of that time to have concocted such a work.
I’ve noticed at least two or three critics who are already buzzing about the roughly 60/40 probability that they imagine this article assigns to the proposition that the Book of Mormon was influenced in a very specific way by “The Late War.”
One of these critics also specifically disclaims any serious knowledge of mathematics — which, since the mathematical content of this article is quite simple and straightforward, suggests to me that this particular critic probably didn’t read the article very carefully.
That kind of inattention may explain their misunderstanding.
What they’re missing is the fact that the piece starts off, for the sake of demonstration and argument, assuming 50% probability. The point is that, even with so high a starting place, a quite generous view of the recently trumpeted “smoking gun” data (80%) would only move the dial to a little more than 60%. Which would make the Johnsons’ claimed discovery rather less than the “silver bullet” that, at least initially, some boasted it to be.
The Schaalje article should be construed as an effort to inject some calm rationality into any future discussions of this matter, not as a concession that Joseph Smith was very likely influenced by “The Late War.”
Dan,
Well put. Thanks.
What is the chance that a farm boy from upstate New York, whose own family’s circumstances were so difficult that he was sent to work for neighbors to help make ends meet, would have even come into contact with an obscure book about the “Late War”. The fact that it was published before the Book of Mormon is interesting, but I doubt there was a copy in the local library near Joseph’s home. Such a book was likely to have been present only in major university libraries, would it not?
Let P equal the probability that Joseph ever saw this book before 1830. My bet is that P is approximately equal to zero.
Keith,
Being an engineer I have to declare your analysis to come with a value P=0 anathema.
At the time the Book of Mormon was allegedly being “translated,” Joseph Smith was hardly a “boy” by his social standards.
Your speculative foundation also seems to be in dissonance with the fact that Joseph did like to read since he was young (that is how he decided to pray about the denominations of his time); and he was actively working on enriching his own academic abilities (by studying Hebrew); and furthermore, that he was trying to get his hands on relics such as the scrolls that yielded the Pearl of Geat Price.
The probability that Joseph had access to a historical novel written in “scripture-like” style is actually pretty high. Still using only speculation, but a little more educated speculation taking into consideration Joseph’s character.
Actually, Joseph’s own mother is on record as saying that, of all her children, Joseph was the least inclined to read, and that he hadn’t read the Bible through. He himself said that he came upon the passage in James that led to his vision essentially by chance.
Moreover, his study of Hebrew came a decade after the translation of the Book of Mormon, when he was the leader of a church — as did his acquisition of the papyri.
And there is no credible evidence at all for his supposed dependence on a historical novel written in the style of the King James Bible.
Daniel Peterson, both Joseph’s father Joseph Smith Sr. and Hyrum Smith were school teachers in the off season. Although Joseph didn’t receive a formal education, it is unlikely that he was not schooled informally by his father and brother. Also, Joseph’s mother wrote that they did not neglect the education of their children. The Late War was an educational text and it’s very likely that Joseph Smith Sr., Hyrum Smith, or Oliver Cowdery had read it and passed it on to Joseph Smith Jr.
In reading through the Preface of the Late War (LW) 3rd edition text it becomes evident that the author (Hunt) intended on this to be used in schools in order to provoke the desire for the young people reading it to be induced to “study the Holy Scriptures,” (p8) among other things. This 3rd edition of the book was published in 1819, and if I am correct, that would place Joseph Smith at the age of 13, or 14, so if he was attending school during this period, I’d say it was fairly likely that he had at least been exposed to this book.
Good article. The audience at mormoninterpreter is too broad to publish a lot of math, but I love and use Bayesian statistics. Is there a version I can read to see the math behind the inference?
Ty,
Thanks for the comment. Surprisingly there isn’t much more to it than Bayes’ rule as shown in the article. I arrived at the conditional probabilities subjectively based on the reasons I noted, as well as experience in genomics where massive searches for base pair sequences involved in various conditions are plagued by false matches.
How much do the posterior probabilities change if you assume prior probabilities of, say, 10% and 90%, just for fun?
If the prior for H is 0.1 and for H* is 0.9, the posterior probability of H is 0.15.
If the priors are switched, the posterior probability of H is 0.94.
So the priors are strongly influential. Oh well. I guess in this case subjective probability means that whatever our beliefs were about the Book of Mormon before we heard about “The Late War”, they probably shouldn’t be changed by it, but it’s one more thing we can put in our “confirmation bias” file, whether we believe or not. I guess that’s better than results telling me that I have to give up the BoM 🙂